Breakthroughs of RF-DETR (2026)
这不是小幅迭代,这是质的飞跃。
60 mAP,意味着它能识别的物体更准、漏检更少、误报率更低。
而6.8ms的延迟,意味着它可以实时跑在普通GPU上。
这两个指标同时满足,业界等了整整五年。
你可能有个疑问:为什么这次突破来自DETR家族,而不是YOLO系列?
因为架构路线不同。
YOLO走的是CNN路线,擅长速度,但全局建模能力受限。
DETR走的是Transformer路线,擅长全局理解,但推理速度曾是痛点。
RF-DETR的创新在于:用神经架构搜索(NAS),找到了一套让Transformer实时运行的”最优解”。
它做了什么?
换掉骨干网络 :用DINOv2替代传统CNN,这个自监督预训练的backbone特征表达更强
简化检测头 :单尺度设计,比Deformable DETR的多尺度设计更轻量
自动化搜索 :用NAS在目标数据集上搜索最优精度-延迟权衡
结果:把Transformer的精度优势发挥出来,把速度劣势压缩掉。
RF-DETR-Nano版本:2.3ms延迟,产线秒级响应。
Deficiencies of YOLO
YOLO 的天才之处其实很简单:把目标检测当作一个回归问题来做。一次前向推理,速度极快,精度也“足够好”。
RF-DETR的核心方法:权重共享与架构搜索
RF-DETR的核心思想是权重共享的神经架构搜索(Weight-Sharing NAS)。研究者们没有设计一个固定的网络结构,而是构建了一个包含多种架构可能性的“超网”(Supernet)。在训练这个超网时,每一次迭代都会随机采样一个“子网”(Sub-net)配置进行更新。
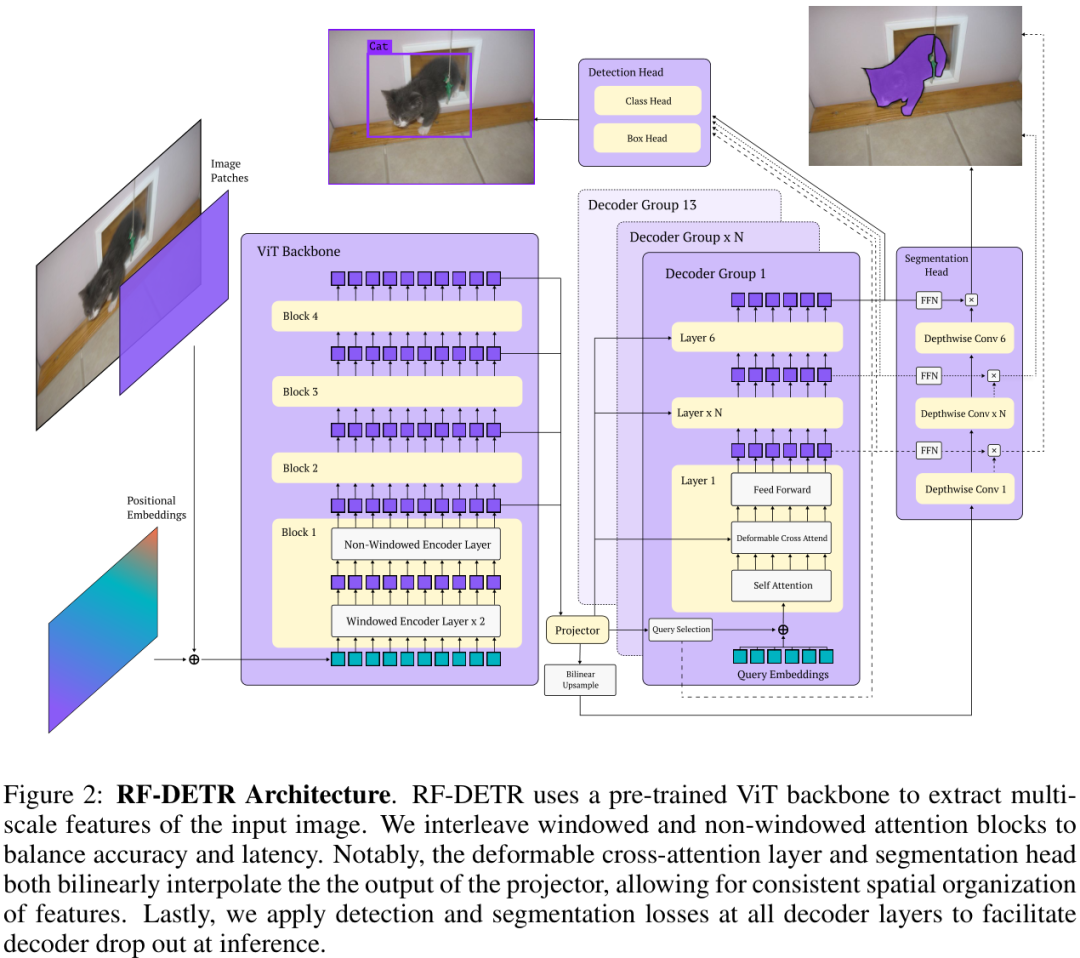
上图展示了RF-DETR的基础架构。它采用预训练的ViT(如DINOv2)作为骨干网络提取多尺度特征,并通过交错使用窗口化和非窗口化的注意力模块来平衡精度与延迟。值得注意的是,可变形交叉注意力和分割头都利用了投影器的输出,保证了特征空间组织的一致性。
训练完成后,这个“超网”就相当于一个巨大的模型库。当需要一个特定性能(比如,延迟必须低于5ms)的模型时,不再需要从头训练,而是可以直接在这个超网中搜索满足条件的最佳子网配置。
Installation
pip install rfdetr import rfdetr print(rfdetr.version)
Training
RF-DETR supports
1
2
3
4
5
6
7
8
my_dataset/
├── data.yaml # 配置文件
├── train/
│ ├── images/ # 训练图片
│ └── labels/ # 训练标签(TXT)
└── valid/
├── images/ # 验证图片
└── labels/ # 验证标签
Where data.yaml
1
2
3
4
5
6
path: ./my_dataset
train: train/images
val: valid/images
nc: 3 # 类别数量
names: ['cat', 'dog', 'bird'] # 类别名称
In each label,
1
2
3
# 格式:类别ID x_center y_center width height(归一化)
0 0.716 0.427 0.108 0.284
1 0.342 0.536 0.075 0.156
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from rfdetr import RFDETRMedium
model = RFDETRMedium(pretrain_weights="rf-detr-medium")
model.train(
dataset_dir="./my_dataset",
output_dir="./output",
epochs=100,
batch_size=8,
grad_accum_steps=2, # 梯度累积,模拟更大batch
lr=1e-4,
lr_encoder=1.5e-4, # backbone学习率(可稍高)
resolution=640, # 输入分辨率(必须是14的倍数)
weight_decay=1e-4,
device="cuda",
use_ema=True, # 指数移动平均
gradient_checkpointing=False, # 节省显存
checkpoint_interval=10, # 每N轮保存一次
workers=4 # 数据加载线程数
)
训练监控与恢复
1
2
3
4
5
6
7
8
9
10
11
# 监控训练
# 训练日志保存在 output/ 目录,可用TensorBoard查看:
tensorboard --logdir=./output/logs
# 从中断处恢复训练
model.train(
dataset_dir="./my_dataset",
output_dir="./output",
epochs=150,
resume="./output/100_epoch_checkpoint.pth" # 恢复训练
)
生产模型建议训练至少100个epoch
batch_size建议8-16,根据显存调整
使用EMA可以提升模型稳定性和泛化能力
checkpoint_interval设为10,每10轮保存一次
Deployment
部署建议:
如果用NVIDIA GPU,强烈建议转TensorRT,延迟可降低40%+
如果用CPU或边缘设备,用ONNX Runtime
如果用移动端,考虑转CoreML(iOS)或TFLite(Android)
导出为TensorRT(GPU加速) ⚠️ 前置条件:需要安装TensorRT,且trtexec在系统PATH中。注意:在哪台GPU上转换,就在哪台GPU上部署(引擎文件不可跨GPU架构迁移)。
from argparse import Namespace from rfdetr.export.tensorrt import trtexec
args = Namespace( verbose=True, profile=False, dry_run=False, )
ONNX转TensorRT
trtexec(“output/inference_model.onnx”, args) 转换成功后,会生成inference_model.engine文件。
使用trtexec命令行(可选)
转FP16加速
trtexec –onnx=inference_model.onnx
–saveEngine=inference_model.engine
–fp16
–useCudaGraph
–warmUp=500
–avgRuns=1000