Introduction

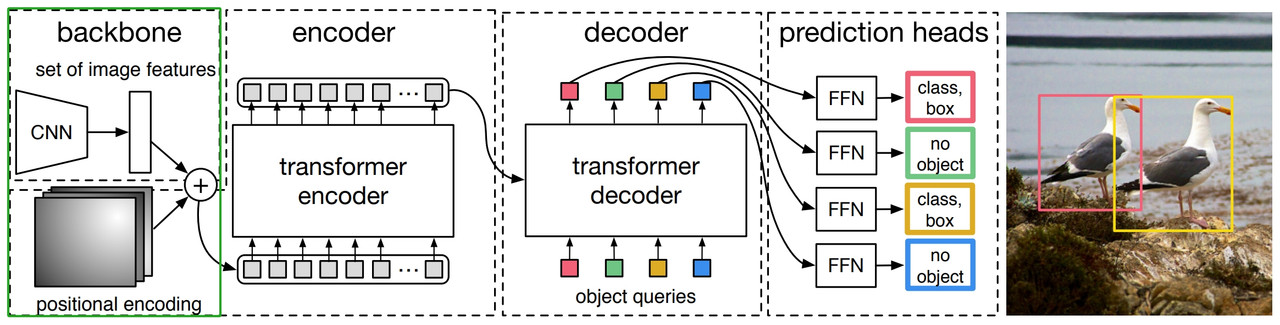
Here is the general architecture of DETR, which is quite straight-forward:
- First is a CNN to extract features (256-Vector)
- Second is a transformer to learn bounding boxes using an encoder and a decoder. 3.
- it uses bipartite matching loss to train a network
Layer norm vs Batch Norm
Layer norm is to take the average of all feature vectors across all input sequences of a specific batch, then divide by the standard deviation so across a batch, all inputs have standard deviation=1. Batch norm is for a specific feature map dimension, take numbers from all sequences across all batches. Across time, the lengths of input sequences might changes. Batch norm will have a larger vairance if input sequences change quite abit, compared to layer norm

Distributed Training
Think of distributed training as:
“Each GPU has its own full copy of DETR, sees a different mini-batch, computes its own loss/gradient, then all GPUs average gradients before taking the same optimizer step.”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
GPU 0: DETR copy, images 0-1
GPU 1: DETR copy, images 2-3
GPU 2: DETR copy, images 4-5
...
GPU 7: DETR copy, images 14-15
Each GPU:
forward
Hungarian matching
DETR loss
backward
Then:
all GPUs average gradients
all GPUs update weights identically
So this is data parallelism, not model parallelism. DETR is not split across GPUs, every GPU stores the full CNN backbone, transformer encoder, transformer decoder, object queries, etc.
Example:
1
2
3
4
5
6
7
GPU 0 has 2 images
Image 1:
ground truth objects: 2
Image 2:
ground truth objects: 4
DETR always outputs a fixed number of queries, say 100. So during training, for image 1, only 2 top queries are matched to the ground truth objects through Hungarian Matching: query 17 and query 33. Then, box loss, and GIoU loss are calculated:
1
L0 = L0_cls + λ_bbox L0_bbox + λ_giou L0_giou
L0_cls : classification loss computed over all 200 queries. In this case, query 17 -> object A, query 33 -> object B, all others are no-object
Box loss is the L1 distance between predicted box vs ground truth:
1
2
3
4
5
6
7
8
9
10
box_17 = [cx_pred, cy_pred, w_pred, h_pred]
gt_A = [cx_gt, cy_gt, w_gt, h_gt]
Then
|box_17 - gt_A|_1 =
|cx_pred - cx_gt|
+ |cy_pred - cy_gt|
+ |w_pred - w_gt|
+ |h_pred - h_gt|
DETR then normalizes the total box loss by dividing it by the number of target boxes. For a single GPU example with 2 objects: L_bbox = 0.55 / 2 = 0.275. In distributed training, divide by the average number of boxes per GPU of this batch. So if GPU 0 has 2 objects, GPU 1 has 4 objects, on average each GPU has (2+4)/2=3 boxes. Then GPU loss is 0.55/3.
Now you might be wndering: the above is equivalent to Lbox_gpu0 + Lbox_gpu1 = 2 * total_raw_Lbox / total_gt_boxes, where 2 is the number of GPU. So why do we leave the result as a scaled result? Because PyTorch DDP will divide the final gradient by the number of GPU.
GIoU: Generalized IoU
Suppose the predicted box and GT box do not overlap. The General IoU cannot tell if they are barely separated, or they are far apart. Assume A = predicted box, B = ground-truth box, C = smallest box that encloses both A and B
GIoU is GIoU(A,B) = IoU(A,B) - [Area(C) - area(aUB)/area(C)]
TODO
-
what is pytorch DDP?