TAL
TAL usually means Task-Aligned Label Assignment or Task Alignment Learning in object detection.
It is used during training, not inference. Its job is to decide:
\[\text{Which anchors / prediction points should be positive for each ground-truth box?}\]The key idea is: a good positive sample should be good at both tasks:
- It predicts the correct class with high confidence.
- Its predicted box overlaps the ground-truth box well.
TOOD introduced Task Alignment Learning to reduce the mismatch between classification and localization in one-stage detectors; modern YOLO implementations use a TaskAlignedAssigner that combines class score and IoU to select positives. (arXiv)
The problem TAL solves
In object detection, each candidate prediction has two qualities:
\[\text{classification quality}\]and
\[\text{localization quality}.\]A bad assigner might pick an anchor because it has high IoU but poor class confidence:
1
high IoU, low class score
or because it has high class confidence but poor box overlap:
1
high class score, low IoU
TAL tries to pick candidates where these two agree.
So instead of using only IoU, TAL uses a task-aligned metric:
\[t = s^{\alpha} \cdot u^{\beta}\]where:
\[s = \text{predicted class score for the GT class}\] \[u = \operatorname{IoU}(\text{predicted box}, \text{GT box})\] \[\alpha, \beta = \text{hyperparameters}\]Typical YOLO-style values are often:
\[\alpha = 1, \qquad \beta = 6.\]The high $\beta$ means localization quality is strongly emphasized.
Intuition
Suppose one ground-truth object has three candidate anchors:
| Candidate | Class score ($s$) | IoU ($u$) | TAL score ($s^\alpha u^\beta$), with ($\alpha=1,\beta=6$) |
|---|---|---|---|
| A | 0.90 | 0.30 | $0.90 \times 0.30^6 = 0.00066$ |
| B | 0.50 | 0.70 | $0.50 \times 0.70^6 = 0.0588$ |
| C | 0.80 | 0.60 | $0.80 \times 0.60^6 = 0.0373$ |
Even though A has the best class score, its IoU is poor, so TAL does not prefer it.
Candidate B wins because it has strong localization.
So TAL says:
\[\text{positive samples should be class-confident and well-localized.}\]TAL assignment flow
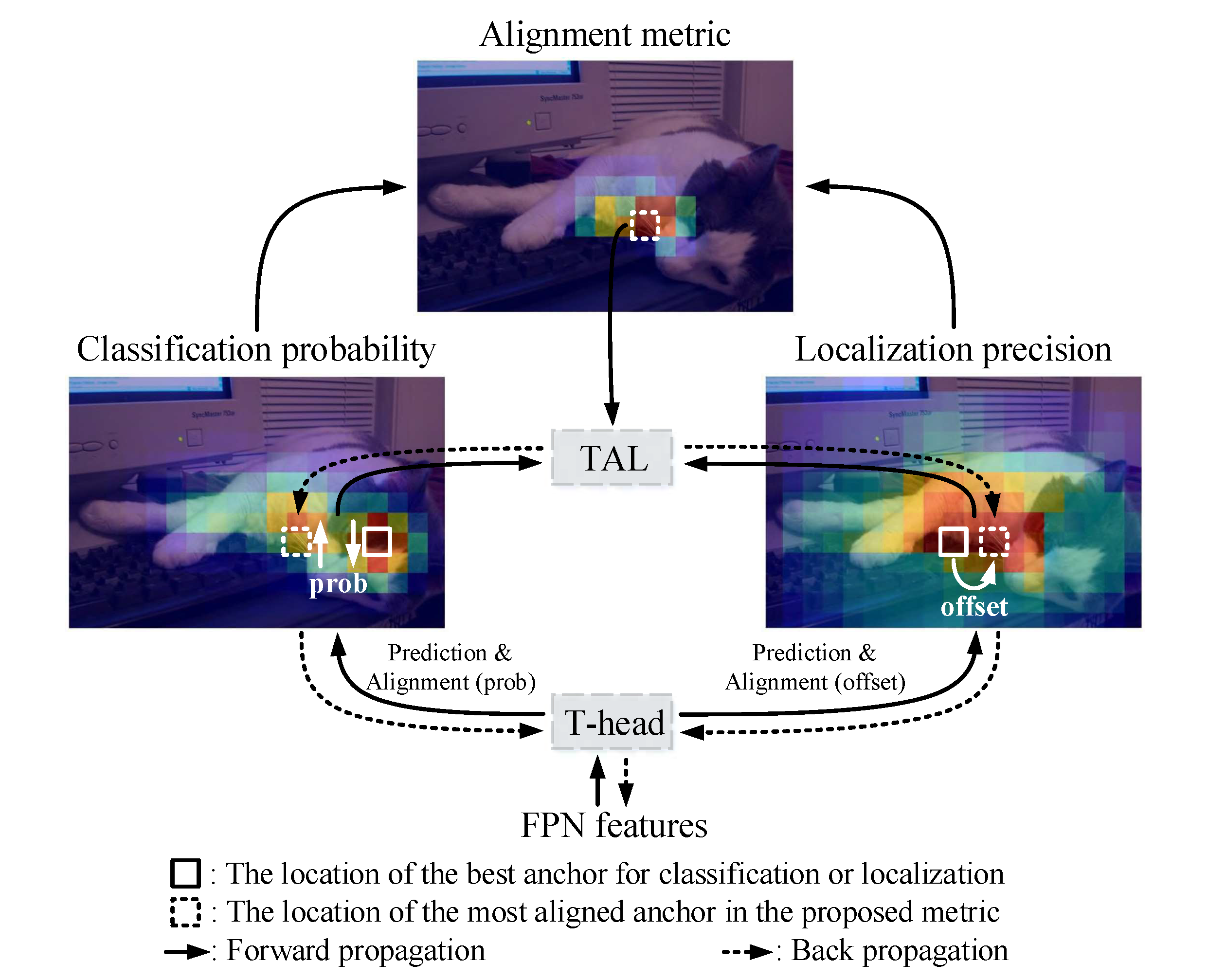
For each image:
- Generate anchor points / prediction points.
- For every ground-truth box, find candidate anchors whose centers lie inside the GT box.
- For each candidate, compute class score (s).
- Compute IoU (u) between predicted box and GT box.
- Compute task-aligned score:
- Pick top-$k$ candidates per ground-truth box.
- Resolve conflicts if one anchor is assigned to multiple GTs.
- Produce training targets for classification and box regression.
Ultralytics’ TaskAlignedAssigner documentation describes this as matching predicted boxes to ground-truth boxes using a metric that combines classification and localization information, with helper steps for selecting candidates inside GTs, top-$k$ candidates, and resolving highest overlaps. (Ultralytics Docs)
Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
def TAL_assign(
pred_scores, # [N, C], class probabilities/logits after sigmoid
pred_boxes, # [N, 4], predicted boxes in xyxy format
anchor_points, # [N, 2], anchor/prediction point centers
gt_boxes, # [M, 4], ground-truth boxes in xyxy format
gt_labels, # [M], class index for each GT
top_k=10,
alpha=1.0,
beta=6.0,
):
"""
Returns:
assigned_gt_idx: [N], -1 means background
target_labels: [N]
target_boxes: [N, 4]
target_scores: [N, C]
"""
N = len(pred_boxes)
M = len(gt_boxes)
C = pred_scores.shape[1]
assigned_gt_idx = [-1 for _ in range(N)]
assigned_metric = [0.0 for _ in range(N)]
target_labels = ["background" for _ in range(N)]
target_boxes = [[0, 0, 0, 0] for _ in range(N)]
target_scores = [[0.0 for _ in range(C)] for _ in range(N)]
# No objects in image: everything is background
if M == 0:
return assigned_gt_idx, target_labels, target_boxes, target_scores
# ------------------------------------------------------------
# 1. Compute candidate mask: anchor point must lie inside GT box
# ------------------------------------------------------------
# candidate_mask[j][i] = True if anchor i is inside GT j
candidate_mask = [[False for _ in range(N)] for _ in range(M)]
for j in range(M):
x1, y1, x2, y2 = gt_boxes[j]
for i in range(N):
ax, ay = anchor_points[i]
if x1 <= ax <= x2 and y1 <= ay <= y2:
candidate_mask[j][i] = True
# ------------------------------------------------------------
# 2. Compute IoU matrix
# ------------------------------------------------------------
# ious[j][i] = IoU between GT j and predicted box i
ious = [[0.0 for _ in range(N)] for _ in range(M)]
for j in range(M):
for i in range(N):
ious[j][i] = box_iou(gt_boxes[j], pred_boxes[i])
# ------------------------------------------------------------
# 3. Compute task-aligned metric
# ------------------------------------------------------------
# metric[j][i] = s^alpha * IoU^beta
metric = [[0.0 for _ in range(N)] for _ in range(M)]
for j in range(M):
cls = gt_labels[j]
for i in range(N):
if not candidate_mask[j][i]:
continue
s = pred_scores[i][cls]
u = ious[j][i]
metric[j][i] = (s ** alpha) * (u ** beta)
# ------------------------------------------------------------
# 4. Select top-k positives for each GT
# ------------------------------------------------------------
positive_pairs = []
for j in range(M):
candidates = []
for i in range(N):
if candidate_mask[j][i]:
candidates.append((i, metric[j][i], ious[j][i]))
# Sort by task-aligned score
candidates.sort(key=lambda x: x[1], reverse=True)
# Keep top-k
selected = candidates[:top_k]
for i, task_metric, iou in selected:
if task_metric > 0:
positive_pairs.append((j, i, task_metric, iou))
# ------------------------------------------------------------
# 5. Resolve conflicts
# One anchor may be selected by multiple GTs.
# Usually keep the GT with the highest IoU.
# ------------------------------------------------------------
for j, i, task_metric, iou in positive_pairs:
old_j = assigned_gt_idx[i]
if old_j == -1:
assigned_gt_idx[i] = j
assigned_metric[i] = task_metric
else:
old_iou = ious[old_j][i]
if iou > old_iou:
assigned_gt_idx[i] = j
assigned_metric[i] = task_metric
# ------------------------------------------------------------
# 6. Build training targets
# ------------------------------------------------------------
for i in range(N):
j = assigned_gt_idx[i]
if j == -1:
continue
cls = gt_labels[j]
target_labels[i] = cls
target_boxes[i] = gt_boxes[j]
# Soft classification target.
# Many implementations normalize this metric before using it.
target_scores[i][cls] = assigned_metric[i]
return assigned_gt_idx, target_labels, target_boxes, target_scores
Important detail: target score normalization
Many TAL implementations do not simply use raw
\[t = s^\alpha u^\beta\]as the final classification target. They normalize it using IoU and the maximum alignment score for each GT.
A common idea is:
\[\hat{t}_{i,j} = \frac{t_{i,j}}{\max_i t_{i,j}} \cdot \max_i u_{i,j}\]So the best aligned candidate gets a target score close to the best IoU quality.
Pseudocode:
1
2
3
4
5
6
7
for each gt j:
max_metric = max(metric[j][i] for selected positive i)
max_iou = max(ious[j][i] for selected positive i)
for selected positive i:
normalized_score = metric[j][i] / max_metric * max_iou
target_scores[i][gt_label[j]] = normalized_score
This makes the classification target reflect localization quality.
Small numeric example
Suppose one GT has label "car" and four candidate predictions.
Use:
\[\alpha = 1, \qquad \beta = 6, \qquad top_k = 2.\]| Anchor | Class score (s) for car | IoU (u) | TAL metric (s u^6) |
|---|---|---|---|
| A | 0.95 | 0.20 | (0.000061) |
| B | 0.60 | 0.70 | (0.0706) |
| C | 0.80 | 0.55 | (0.0221) |
| D | 0.30 | 0.85 | (0.1131) |
TAL selects the top 2 by metric:
1
D and B
Not A, even though A has the highest class score.
Why?
Because A is class-confident but badly localized.
TAL prefers predictions where classification and localization are aligned:
\[\boxed{ \text{high class confidence + high IoU} }\]TAL vs IoU-only assignment
IoU-only assignment:
\[\text{score} = u\]Uses only box overlap.
TAL assignment:
\[\text{score} = s^\alpha u^\beta\]Uses both class confidence and box overlap.
So TAL asks:
Is this prediction both confident about the right class and spatially accurate?
That is why it is called task-aligned: it aligns the classification task and localization task during label assignment.