Tesla’s Challenges @2021
- Back then their lane detections are still very un-usable.


- per-camera detect then fuse: how can you tell if they belong to the same truck? REcovering the shape of a big truck is a challenge

- How fast is the truck traveliing? is it moving or doubled parked? is there a pedestrian behind the car?

- Lane marking is for the future. How to preserve them in the feature space?

- Tesla’s solution: Top-Down pixel (“local map”) that provides a uniform perspective, adding features temporally is viable. This is basically Bird-Eye-VIew, or BEV.
The Evolution of Tesla Vision
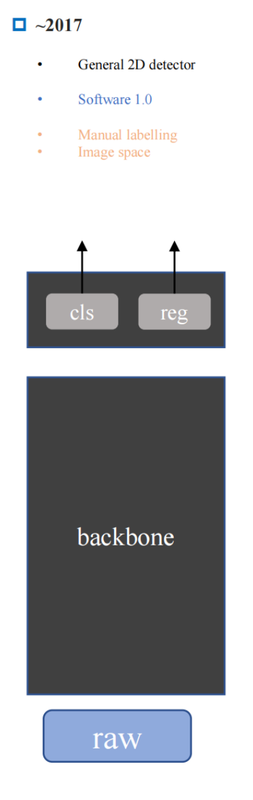
- 2017: range detection (reg)is that right?? and classification
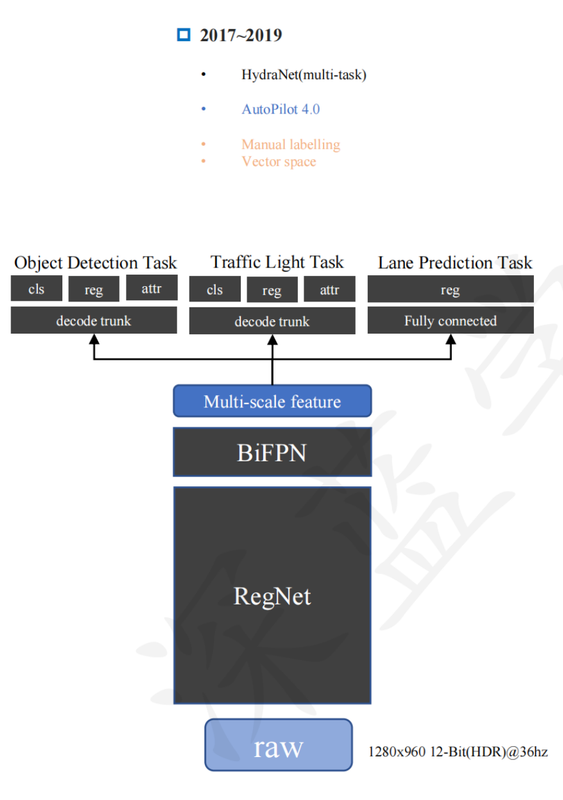
- multi-model and multi-tasking???

- feature queue and vector space. Supports ??
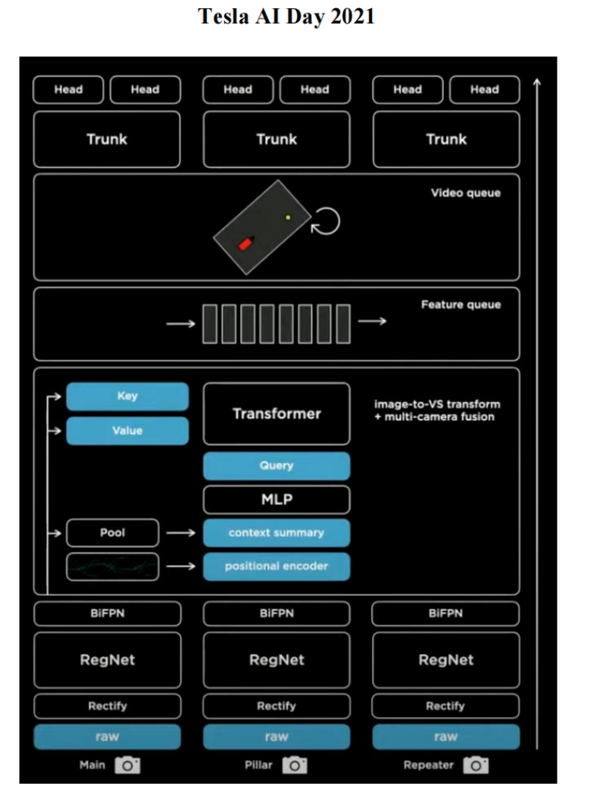
- Use a transformer to elevate image domain into 3D vector space (similar to BEV??)
- FEature Queue: cache spatial and temporal features
- video module: fuse spatial and temporal features
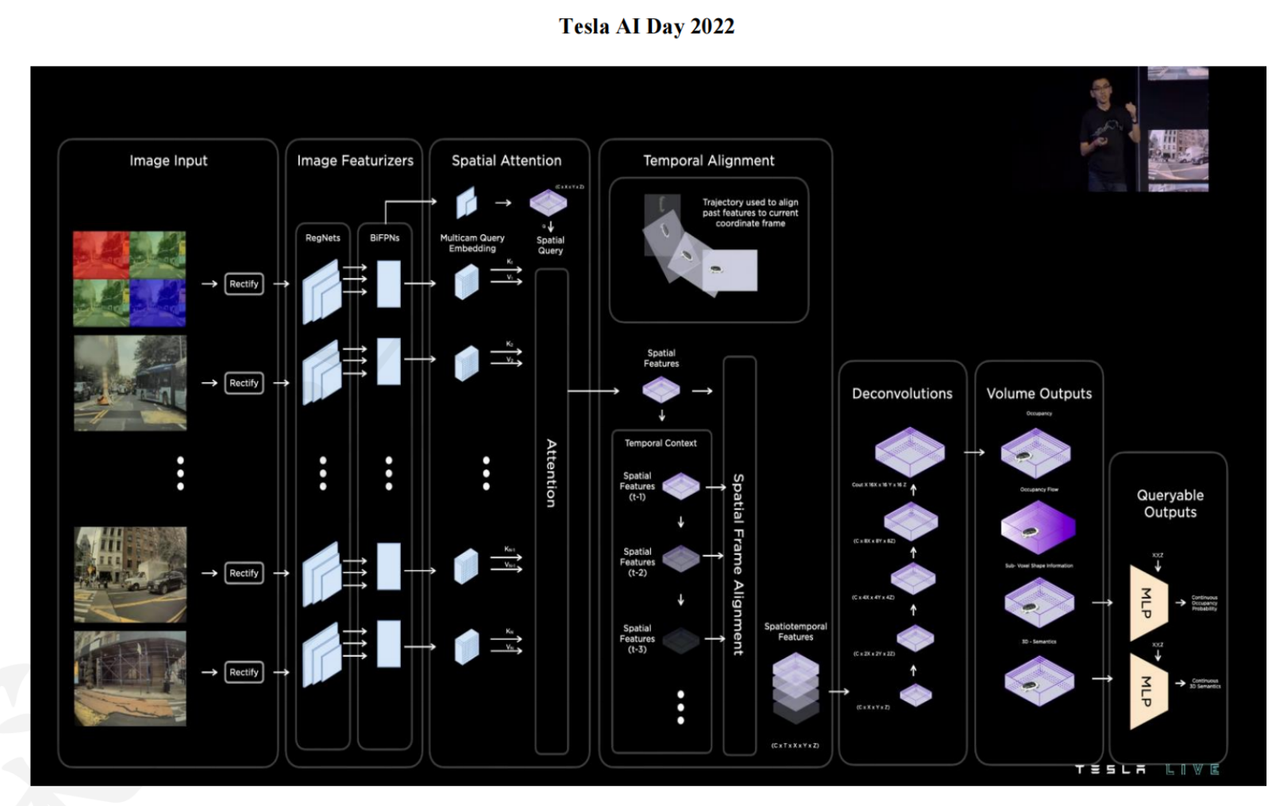
- Take in images taken at multiple times, rectify them
- feed them into image featurizers
- generate key and value for each image, in the meantime generate a spatial query of all these images together
- Generate spatial features. These features are aligned at the same time T?
Tesla is the only company that does not use HD map, visiion only achieve NOA in cities (what is NOA??). Based on vector space. Their Data closed loop is extremely strong. Below is from their 2022 Demo - NOA: navigate on Autosteer now, but previously, navigate on autopilot
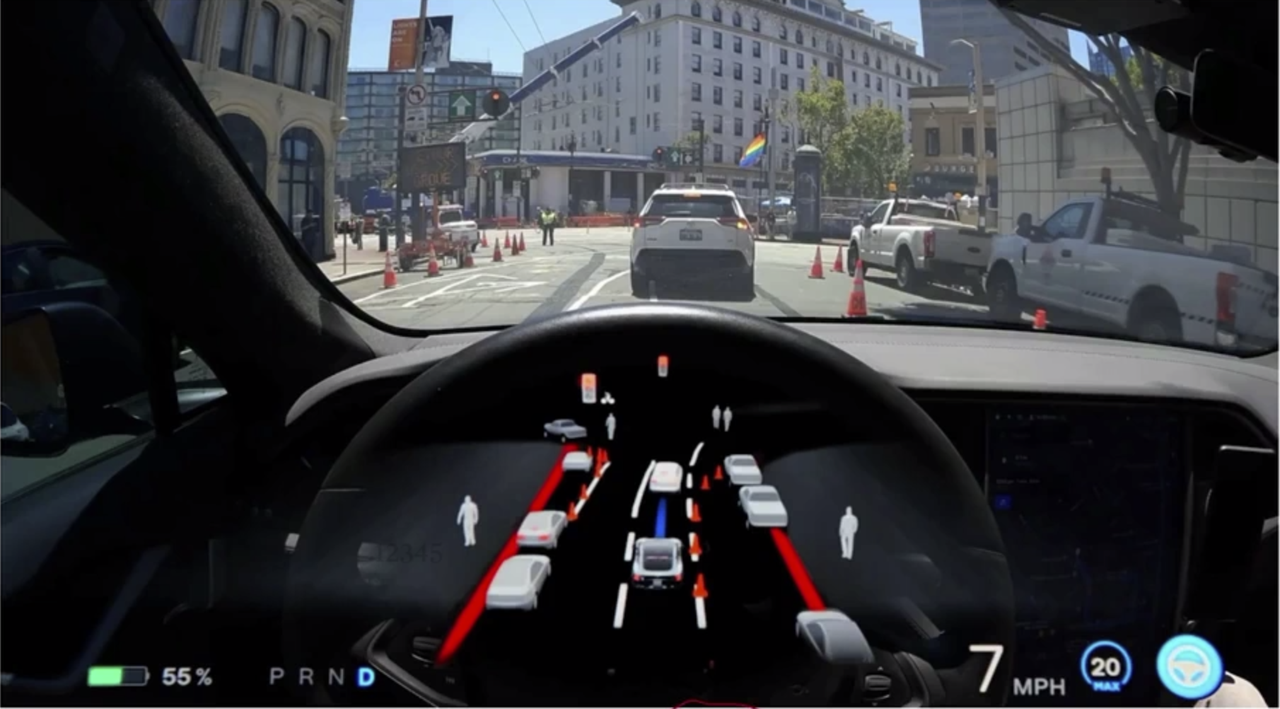
What Tesla wants to achieve for a L2+ (even FSD)?
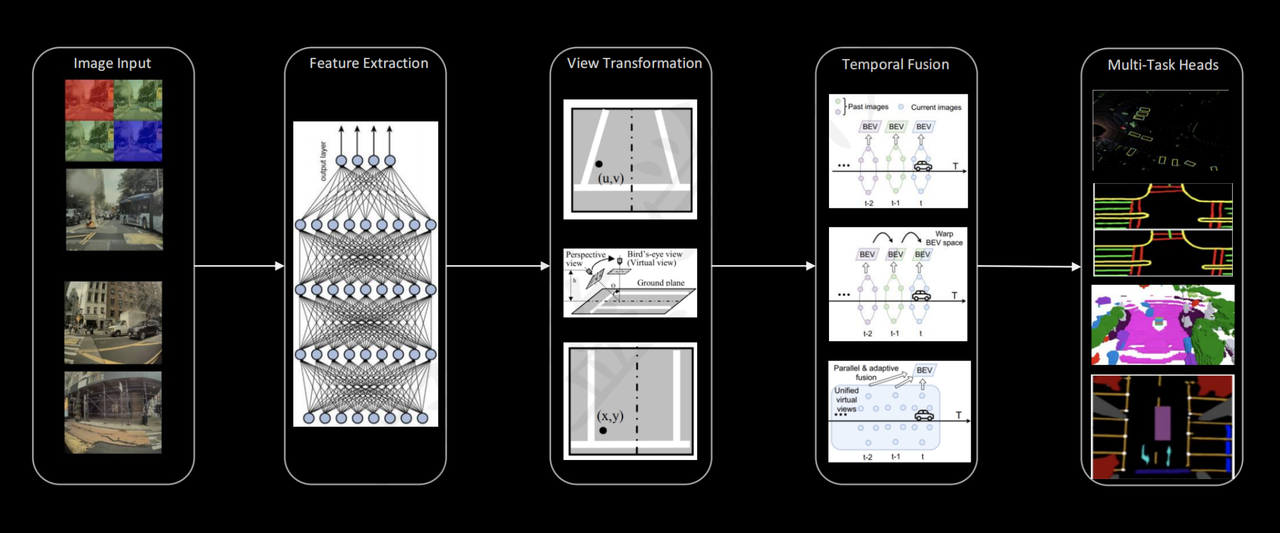
- Feature extraction, this can be done using resnet, etc.
- Transform features to the same view?? (but isn’t view transform supposed be before feature extraction???)
- Align spatial features onto the same view (vector space, or BEV)
- temporal fusion aligns multiple consecutive frames (why would you need to do that since you have already algined spatial feature? )
- multi-task heads like occupancy grid, parking, etc. can use the BEV representation ??
Idea for A Model That Reconstructs Occupancy in Real Time
How would you train though, like where do you get your depth measurements
-
companies often build an offline auto-labeling / reconstruction pipeline that may include SLAM, SfM, bundle adjustment, tracking, multiview stereo, map fusion, and other heavy optimization. The pipeline is:
collect synchronized multi-camera video + calibration + ego motion run a heavy offline reconstruction / tracking stack generate pseudo-ground-truth labels: 3D points / surfaces object tracks occupancy lane geometry free space train the online network to predict those targets from raw camera input alone
The offline system may produce:
1
2
3
4
sparse depth
semi-dense depth
dense depth
surface estimates
Then the network predicts depth or occupancy and is penalized against those targets.
Instead of supervising depth directly, you voxelize the reconstructed scene into:
1
2
3
occupied
free
unknown
This is often closer to what driving actually needs.
That offline system produces training targets that are much better than what the real-time car can compute onboard. The offline system reconstructs the scene and produces supervisory signals; the online network learns to predict a compatible world representation directly from images.
Sois the point for BEV network is to reconstruct a similar quality local 3D map to the offline processed one, using onboard cameras during runtime?
Feature consistency / reprojection loss
You can also say:
predict depth or 3D features project them into another camera/time compare with observations there
That gives a self-supervised or weakly supervised signal.
“Multiview geometry = find feature points + epipolar geometry + sparse point cloud?”
The classical pipeline is:
detect/match feature points across views or across time use epipolar geometry to reject bad matches estimate relative pose triangulate matched points into 3D refine with bundle adjustment
That gives a sparse 3D point cloud.
Then you can go further with:
multiview stereo plane fitting temporal fusion semantic segmentation object-level reconstruction
to get denser scene structure.
So your statement is correct, but sparse point clouds alone are often not enough for autonomous driving training. You usually want something richer:
surface estimates lanes curb geometry occupancy volumes tracked objects
A nice summary sentence:
Epipolar geometry and triangulation give the geometric skeleton; the full offline pipeline densifies, cleans, and semantically organizes it into usable training targets.
View transformation:
- IPM: (inverse perspective mapping): convert 2D points from images to 3D points without using depth information , by assuming points lie on an arbitrary plane.
For a BEV cell at world position (x, y), you can:
assume or predict some height/depth hypothesis use camera calibration to project that 3D point into the image plane sample the image feature map at that image coordinate write or accumulate that sampled feature into the BEV cell
This is often called:
unprojection lifting splatting view transformation
Depending on the method, you may:
use explicit geometry predict a depth distribution per pixel use attention instead of explicit projection do voxel lifting then collapse to BEV
5) Why feature warping is preferable to raw image warping
Because the features already encode useful semantics:
edges lane markings car-like structure curb-like structure texture invariance lighting robustness
If you warp raw pixels into BEV, you get a strange distorted top-down image with lots of artifacts and no real understanding.
If you warp learned features, the network can preserve meaning, not just appearance.
That is why the usual order is:
image -> backbone -> feature map -> geometric lifting/projection -> BEV/world fusion
not:
image -> hard warp -> backbone
6) The subtle issue: one image pixel does not have a known depth
This is exactly why BEV lifting is hard.
If I take one image feature at pixel (u,v), it corresponds not to one definite 3D point, but to a whole ray in 3D unless depth is known.
Different methods solve this differently:
Method A: Flat-ground assumption / IPM
For roads, assume points lie on the ground plane. Then each image point maps to one BEV point.
Good for lanes/road surface, bad for tall objects.
Method B: Predict depth distribution
For each image feature, predict probabilities over multiple depth bins. Then “lift” the feature along the ray into 3D/BEV.
This is common in modern BEV methods.
Method C: Attention-based cross-view transform
Instead of explicit triangulation, let transformers learn how image features correspond to BEV queries.
Method D: Occupancy prediction
Predict whether cells/voxels are occupied, sometimes bypassing an explicit dense metric depth map.