Embedding, Encoding
An embedding is a learnable vector, part of an embedding table A, which is similar to a fully connected layer y = x @ W.T + b. However, an embedding usually does:
1
one_hot(index) @ embedding_table[index]
In DETR, we use all vectors every forward pass.
Encoding is the result of processing soemthing, like memory = encoder(src, pos=pos_embed), memory is an encoding of the image features.
DETR (2020, Facebook AI)
Here is the original Paper of DETR Here is a well-written blog post on DETR
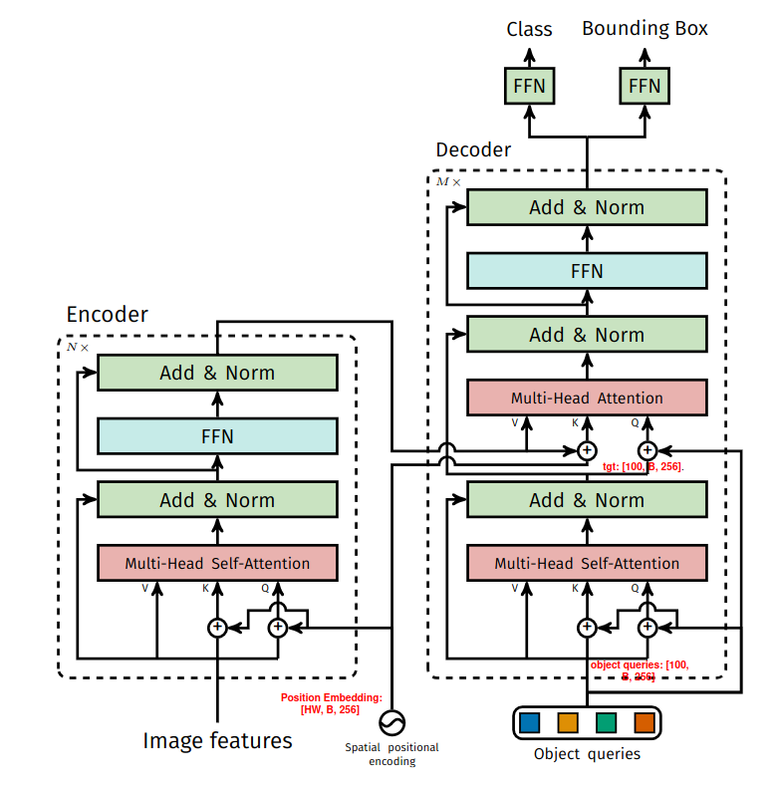
The general DETR idea in short: image [B, 3, H] -> CNN backbone feature map [B, C_backbone, H, W]-> -> 1x1 conv projection to Transformer hidden dim [B, 256, H', W'] -> flatten into visual tokens [B, H' * W', 256] -> Transformer encoder [B, H' * W', 256] -> Decoder with learned 100 object queries [B, 100, 256] -> prediction head: one class + one bounding box / object query class logits: [B, 100, num_class + 1], bbox: [B, 100, 4]

num_class+ 1 is dataset classes + no object-
DETR uses a CNN backbone to yield a lower resolution feature map instead of cutting the original image into 16x16 patches. The flattened visual token can be thought of as a 256 feature embedding / token at one spatial location of the CNN feature map
- These embeddings will go through the encoder. Each object query bnecomes one object prediction slot. For every query, DETR predicts a class label, a confidence score, and bbox.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class DETR:
def __init__(self):
self.num_queries = 100
self.hidden_dim = 256
# Learnable object-query embedding matrix
self.query_embed = nn.Embedding(
num_embeddings=100,
embedding_dim=256
)
def forward(self, src, mask, query_embed, pos_embed):
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1) # Flatten: [H*W, B, C]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # image positional embedding: [H*W, B, C]
# object query embeddings: [num_queries, C]. repeat for each image in batch:
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# image mask: [B, H*W]
mask = mask.flatten(1)
# decoder content input: [num_queries, B, C]
tgt = torch.zeros_like(query_embed)
# encoder processes image tokens
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# decoder updates blank object slots by attending to image memory
hs = self.decoder(
tgt,
memory,
memory_key_padding_mask=mask,
pos=pos_embed,
query_pos=query_embed,
)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
Note, decoder does something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
for decoder_layer in decoder_layers:
# 1. Object queries talk to each other
tgt = self_attention(
query = tgt + query_embed,
key = tgt + query_embed,
value = tgt
)
# 2. Object queries look at image memory
tgt = cross_attention(
query = tgt + query_embed,
key = memory + pos_embed,
value = memory
)
# 3. Feedforward network refines each object slot
tgt = feed_forward(tgt)
class_logits = class_head(tgt)
boxes = bbox_head(tgt)
- Position Embedding: [HW, B, 256] “this feature comes from this spatial location”
- tgt is the output from each decoder MHSA layer output. To begin with, it’s just zero. Then we form the key and query next MHSA layer with
tgt + query - Object queries are learned embedding for object slots. Basically, 100 different search prompts. One great insight from DETR is the interpretation of object queries
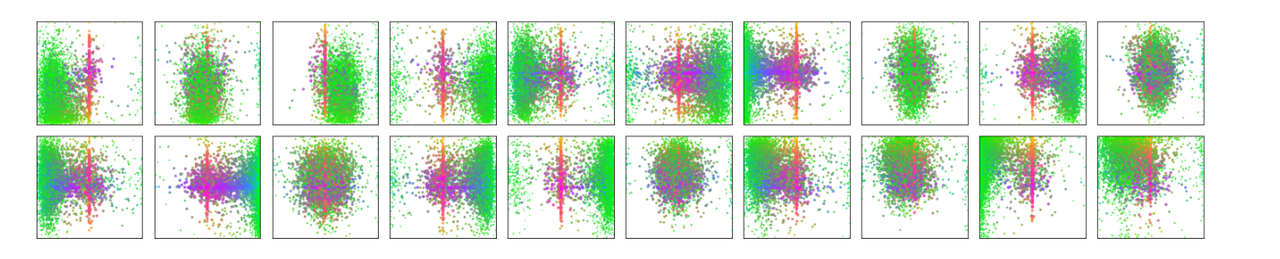
This image was generated by:
- Feed all COCO val images into DETR.
- For 20 out of 100 decoder query slots, record the predicted bounding box.
- Plot the center of that box as a point.
- Color the point according to box size/aspect ratio.
This image shows that each object query does learn a different part of the image to pay attention to, thoughout the entire COCO dataset. Though at the beginning, each object query is unbiased, over 6 decoder MHSA layers and training, each object query learns a unique distribution of object centers to look at.